We liberate millions of students and teachers from exam-oriented education by reducing attention and time dissipated on training, with the solution entirely directed by mathematical models.
– Hisen Zhang
Overview
The Problems
What is the Problem
- A lot of wastes for printed past paper booklet
- Great difficulty to make up a paper for internal assessment
- No focus for students while practicing
Our Objectives
- Reduced wastes
- An easier life for teachers
- and students.
How We Achieve it
- Digitize quiz bank
- Automate paper make up process
- Introduce AI Director
FAQ
Q1 : What is P.A.E.?
An AI directed question paper assembler. P.A.E. stands for “Paper Assembly Engine”.
Students may use it for exam-training and teachers are allowed to learn about their student’s progress.
Q2 : What’s Special?
The entire process is directed by Artificial Intelligence.
Although many digital quiz banks seem to be handy, a traditional quiz bank requires user to select questions manually. Unlike other quiz banks (such as the one offered by THE INTERNATIONAL BACCALAUREATE®), our system enables 100% automated process, from selection to assembly to response collection. This feature is achieved by the
Data Flow Cycle, a fundamental idea introduced later in this chapter.
About the System
To understand the complete system, it would be better to first get familiar with the data flow loop between three main subsystems.
The Data Flow Cycle
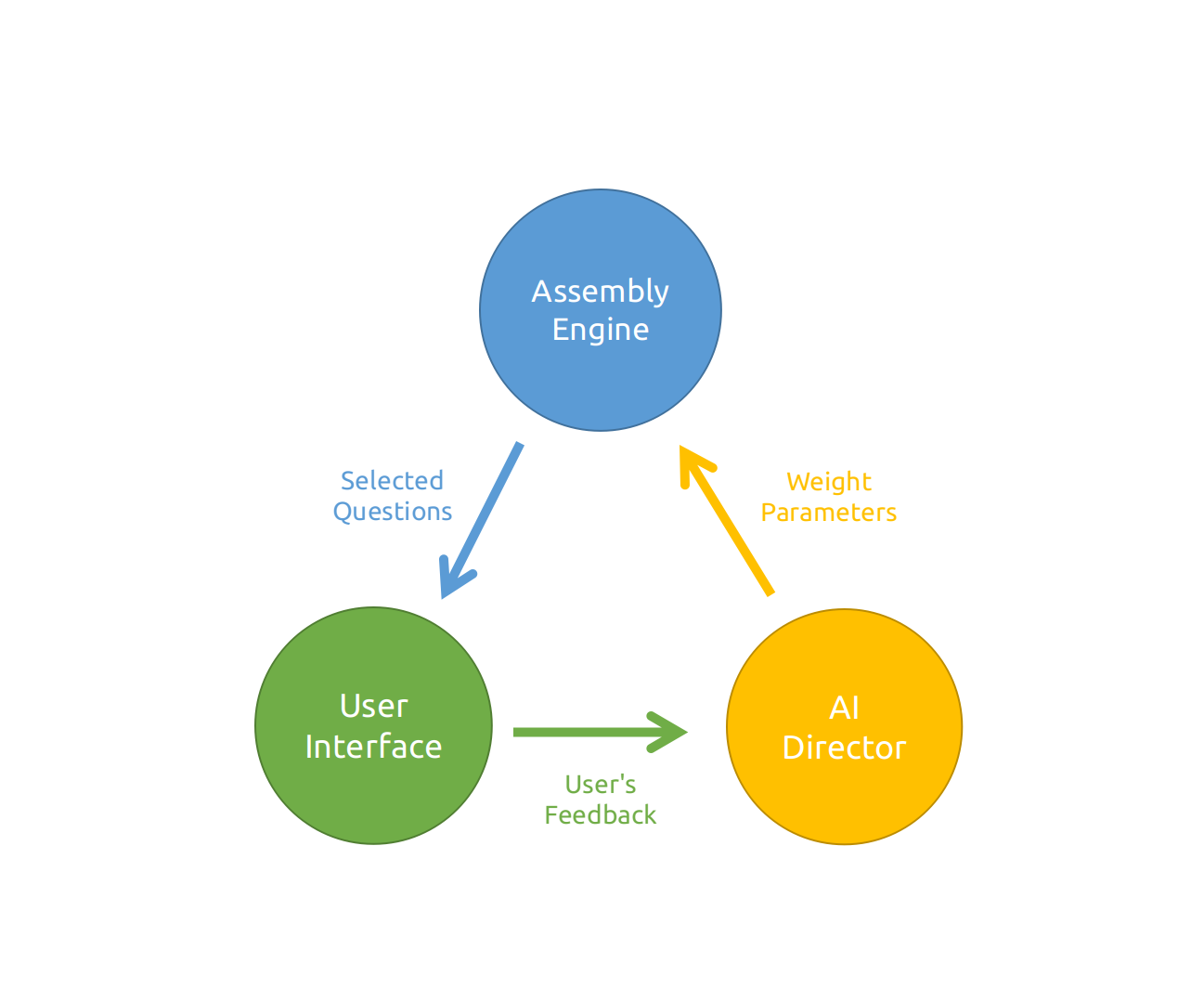
The entire system consists of three subsystems: AI Director, Assembly Engine, and User Interface.
The data work cycle works like this:
- The
AI Directorgenerates weights depending on feedback. - The
Assembly Engineassembles question papers referring to the weights. - The
User Interfacedisplays papers assembled and collects feedback.
Note: Chapter 2 describes the three subsystems in details.
The Complete System
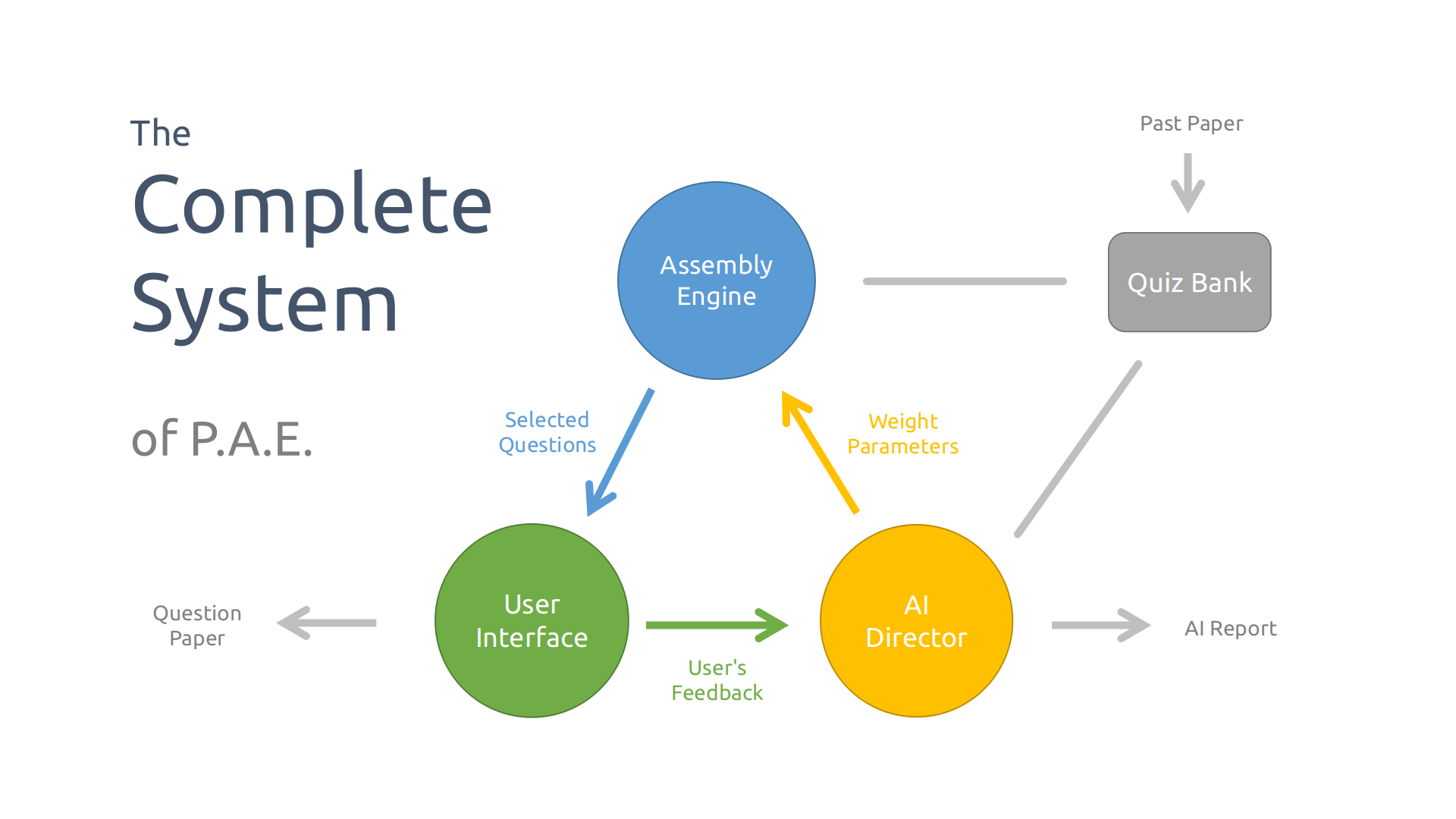
Beside the subsystems, other components are labeled in the diagram above. The input of the system is the past paper published on the Internet. The output has two parts: the generated question paper and the AI reports.
Past Paper
For this program, the A-Level series question paper published by Cambridge International Examination is applied. They are available to qualified centers and teachers.
Question Paper
The User Interface sends AJAX requests to the API. The return is in JSON. Then the Javascript code in user’s browser refreshes the web page partially.
The question paper is presented in HTML.
AI Report
AI report is both available to students and teacher. The contents are generated for two groups of users respectively. For students, this report details their strength and weakness; for teachers, this shows the overall statistics in the system, and a specific profile for each student as well.
Quiz Bank
In this project, the quiz bank is implemented with sqlite3. The database is light enough to operate and stable enough to keep the questions.
In most cases, the database is read-only. When multi-user feature works, another database for storing account data should be deployed separately.
Both Assembly Engine or AI Director may access to the quiz bank.
Components’ Visibility
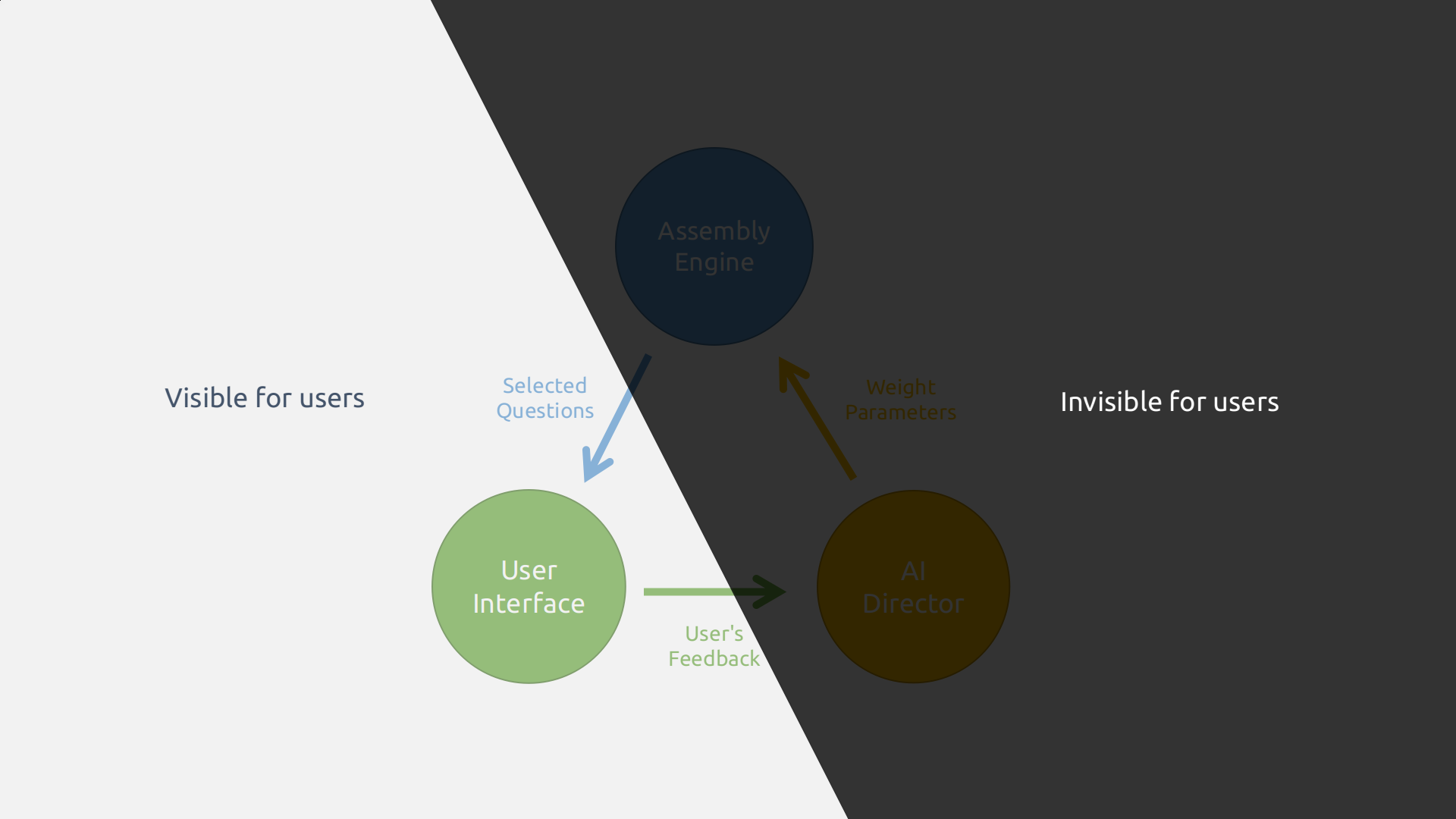
Only the User Interface is visible to the users. The rest parts are running in the background. Communication across the line of visibility is implemented with HTTP restful API.
Components
Assembly Engine
The assembly engine takes weights as input. The questions selected are based on weights on different topics. The output is transmitted in JSON via the API.
There are different modes for assembly engine. The mode is specified implicitly (or explicitly in some occasions) with the parameters passed to the API.
The interfaces and usage are listed below:
| Interface | Method | Parameter | Comment |
|---|---|---|---|
| /paper/ | [GET] | topic_keyword, similar_to | If topic_keyword is specified, fetch the questions with the keyword; else select the questions most similar to the value. |
User Interface
The user interface takes the JSON from paper information to render them in the web page. When users type command into the search bar, the Javascript code loaded into user’s web browser will send AJAX requests to the back end. The API server at the back end calls the assembly engine and response with the information of question in JSON.
Sample Response
1 | { |
Explanation to some important fields:
| Field | Type | Comment |
|---|---|---|
| citation | int | How many times the question is referred |
| id | int | The unique id of the question in the quiz bank |
| q_ans | string | The answer to the question |
| q_path | string | Add this to the images’ src attribute |
| quality | int | The mark for quality. Currently reserved. |
AI Director
The main role played by AI Director is to decide which question to be selected from the quiz bank.
Pre-Processor
Since the quiz bank is designed to be updated once a season, it does not make sense to run AI codes over the quiz bank over and over. The idea here is to pre-process through all records in the database and store this information (mainly matrices) on the disk. This method also accelerates the process for question selecting since the decision is made by referring to the matrices with calculated values.
There will be more introduction to this component in later chapters.
Accessories
Cutter
The cutter is responsible for cutting the images of questions and fetch their answers from the input, which is the past paper in PDF format, and append these data into the database.
The cutter should be an important component (or, subsystem). However, since this part of the program is highly curriculum related, and only little usage of this function (the update interval is supposed to be 4 months or so), I decided to classify this function as an accessory.
By the way, this part takes a great portion of time over the development.
Algorithms
Most algorithms applied in this program are included in the pre-processor.
TF-IDF
This method lowers the weights for stopwords (i.e. “and”,”the”) and therefore it highlights the featured words. Sorting these words gives a keyword list used to generate word vectors.
Cosine Similarity
The cosine distance applies to vectors in spaces with more than three dimensions as well. This made it possible to calculate the similarity between two vectors. The result of cosine distance gets closer to zero if two vectors are more alike. The similarity is defined by $1-\cos\theta$.
Therefore the difficulty is to generate a vector for each question: and such a vector must be able to display the feature of that question. An assumption is made: the words appeared in the text do have a strong connection to the topic behind. For instance, the word “spring” will come along with the topic “elastic deformation”.
ISODATA & K-Means
K-Means clustering works based on Euclidean distance. With the given number of K, the output of this algorithm is the K cluster, Such a method is very straightforward.
However, this is also the problem. Although only once hyperparameter needs to be specified, The value of K is difficult to decide. In practical, the K is often decided arbitrarily.
As an improvement to the K-Means algorithm, Iterative Self-Organizing Data Analysis Technique will refer to the K value given, but modify the value during the process as well. This is achieved by splitting and merging the clusters once according to the following conditions:
- If the standard deviation within a cluster exceeds $\theta_{split}$
- If the distance between two centroids are closer than $\theta_{merge}$
- etc.
Innovations
Introduction to Innovations
While programming this system, some functions already integrated into standard or third-party modules do not fit my case perfectly. For instance, I first planned to use CSV (comma separated values) to store the matrix of cosine similarity. However, storing in text not only occupies large storage space but also has a loss in data precision. Therefore I defined a type of file to store this matrix efficiently.
CSM: Cosine Similarity Matrix storage
As suggested in earlier chapter, the matrix of cosine similarity looks like this:
1 | [[0.2432432], |
The calculated cosine similarity matrix is symmetrical. This means it is possible to cut the size in half when it comes to storage, whether in the memory or on the disk. To be precise, the actual elements required to restore a complete n by n matrix is:
$\frac {1}{2}n (n-1)$
In this case, the values are in the type of float. Each float element has the size of 4 bytes. Therefore the total size of the file is $2n(n-1)$ bytes.
The built-in function in Python repr() convert the objects in strings, and they can be restored to object with eval(). However, float data here must experience loss in precision because the data is rounded to some digits for saving storage space.
The comparison below may show how the solution makes a difference. Rounded to 5 digits, a “float” stored in string occupies 8 bytes on average (with “0.” and a comma). n is the dimension of the matrix.
| n | CSM | Round(5) | Round(8) |
|---|---|---|---|
| 100 | 19.8 KB | 39.6 KB | 54.5 KB |
| 1000 | 2 MB | 4 MB | 5.5 MB |
| 10000 | 200 MB | 400 MB | 550 MB |
Some advantages of applying CSM format:
No loss in data precision
More compact storage
In reality, the first 12 bytes are reserved for storing the dimension of the matrix and the values on the symmetrical axis. The following table shows the header of smc files.
| Field | Type | Size | Comment |
|---|---|---|---|
| SIZE | unsigned long | 8 | Dimension |
| SYM_VAL | float | 4 | Values on the symmetrical axis |
| DATA | float | 4 | Elements in the matrix |
ISODATA Python Module
Some projects like PyRadar do integrate the function of ISODATA clustering for image processing. However, there is not a ISODATA library for general purposes. Therefore I started to implement the code from scratch. For making the life easier for other programmers, I decide to make it publicly available.
This module is for general purposes by allowing vectors as input and the vectors in clusters as output.
Reflection
“I have a Dream”
I have a dream.
I have a dream, that students may have some spare time, doing some coolest things with coolest people. This project helps by raising the efficiency of training.
I have a dream, that teachers don’t have to study for the exams, but to study in the fields they are talented. P.A.E. automate this process with machine learning.
I have a dream, that students may join pure project-based study, instructed by their teachers, instead of being prisoned by examinations…
I have a dream.
Limitations and Improvements
Postulates
This system is designed to be valid based on these following ‘believed-to-be-true’ statements:
- “Practice makes perfect.”
- The keywords show some features of the text.
So far these postulates are widely validated. However, no solid shreds of evidence suggest they are truth. In other words, if these statements are proved to be wrong, the system may not be effective as it was proposed.